1. 介绍
cache就是人们所说的缓存。我们这里所说的cache是web上的。对用户来说,衡量一个网站是否具有良好的体验,其中一个标准就是响应速度的快慢。可能网站刚上线,功能还较少,数据库的记录也不多的情况下,网站可能访问速度比较快,也不需要优化。但是随着网站发展起来,功能越来越多,数据库越来越大的时候,这个时候可能网站的访问速度就会下降。无论网站刚上线初期还是到一定程度的情况,我们都希望网站具有良好的响应速度。
而要怎样提高页面响应速度呢?其中一个方法当然就是本章所说的cache。先来说整个网站的请求响应的过程:用户从浏览器发出一个请求,比如点击一个按钮或在浏览器输入网址回车,然后经过层层的网络最终到达网站的服务器,假设我们用nginx来作为静态文件服务器,而用unicorn作为运行ruby代码的容器,先经过nginx处理,nginx一般是处理html,css,js的,它会默认处理带有htlm,css,js后缀的请求,比如/articles.html,如果发现有它处理不了的,比如/articles/1这样的请求地址,因为nginx没有匹配这样的地址,就会反向代理到unicorn,unicorn是运行ruby代码的,它会连接数据库,它可能从数据库取到一些数据,把数据处理完,再返回给nginx,最nginx返回给用户。
这里所说的unicorn是运行ruby代码的应用容器,当然也可以是php或java的容器,比如tomcat等。道理是一样的。
server {
listen 80 default_server;
server_name www.rails365.net;
root /home/yinsigan/rails365/current/public;
...
try_files $uri/index.html $uri @rails365;
location @rails365 {
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Host $http_host;
proxy_redirect off;
proxy_pass http://rails365;
}
...
}
上面是nginx的配置文件的部分内容,网站根目录是/home/yinsigan/rails365/current/public,具体看try_files $uri/index.html $uri @rails365;这一句,当用户在浏览器请求/about.html地址时,nginx会首先看网站根目录有没有about.html这个文件,有的话就直接读出根目录下的about.html,因为nginx默认会对html后缀的文件作处理的,读完后直接返回响应给用户,就完成了这一次请求,没有的话,就会请求@rails365的内容,也就是反向代理到unicorn服务器。
整个请求过程无论哪一阶段都是需要时间的。而最影响速度也最容易产生性能瓶颈的主要有三个地方:
- nginx处理静态文件的过程
- nginx和unicorn交互的过程
- unicorn和数据库交互的过程
第一点,nginx处理静态文件的过程主要指的是处理图片、javascript、css文件的过程。假如这些文件数量很多,体积又很大,在这一过程是需要耗费很多时间的,但是这些可以通过nginx的gzip来压缩大小、浏览器cache或CDN等技术来解决,这点不在cache的范围内。
第二点,nginx作为反向代理服务器和应用服务器unicorn的交互也是需要时间的,nginx也作为静态服务器只能处理一些简单的静态服务器,而unicorn可以处理复杂的逻辑,不过最后unicorn还是要转化成html给nginx,nginx再给用户,所以整个请求过程如果不到unicorn,由nginx直接返回那就更好了。这样是能大大增快响应速度的,因为不仅nginx到unicorn那步少了,而unicorn到数据库这一步也不用了,所以还是有效的,但是它有一些不好的弊端,具体的我们下面会说到。第二点的解决方案是通过nginx的proxy_cache或者文件cache来解决。
第三点,应用服务器和数据库的交互,这个数据库我们一般指的是关系型数据库,比如MySQL、PostgreSQL等。这个过程是很重要且很常见的,毕竟几乎所有网站都需要数据库来存储数据吧,但数据库很庞大时或者对数据库处理不当时,这个交互过程是很耗费时间的,所以我们会在这个过程用redis作为cache来解决。
2. cache的种类
cache有很多种,比如上文提到的文件cache,nginx的proxy_cache,浏览器的cache,html片断的cache,除此之外,还有代理服务器的cache,CDN的cache,数据库级的查询cache。这篇文章我们只会讲述文件cache还有用redis来实现cache的情况。
3. 文件cache
文件cache在上文有提到,就是在nginx和unicorn交互的过程中发挥作用的,就是让请求直接给nginx处理,而不经过unicorn。打个比方,比如要浏览一个博客网站的首页,首页列出了最近的十篇博文,这些博文肯定是存储在数据库中,请求先通过nginx,nginx再通过unicorn,unicorn去数据库取到这些博文,再组装成html文件再给nginx,nginx再给用户,整个过程完成。而文件cache要做的是当unicorn组装成html给nginx的时候,也顺便在网站根目录下生成.html结尾的文件,这样下次访问就不用经过unicorn了,直接在网站根目录取文件就可以了。这种方式,说白了,就是把动态的查询静态化,让请求过程少了,当数据库有查询瓶颈的时候用这种方式是有好处的。但是这种方式有一个弊端,就是有登录系统的情况,比如一个首页,同样是相同的网址,每个人访问就有不同的页面,因为是不同的用户在访问,比如导航菜单,可以就会出现你的名字。文件cache办不到这种事,因为它是根据地址来处理的,比如访问http://www.example.com/articles.html,它会找根目录的articles.html文件,可是这个文件只有一个啊,但我们需要的是有多少个用户就有不同的页面,所以它不好判断,就算判断了,也失去了本来静态化的意义。所以文件cache只适合那种展示页面用的,很多时候并不适用,毕竟现在谁的网站没个登录系统呢。
4. 用redis实现cache的原理
上文也有提到文件cache的情况,cache的原理就是用一种访问更快的介质或更少的请求来提高查询速度。用redis来实现cache也是一样的道理。我们先不管redis最终会存储什么内容,我们有个对比的介质,那就是关系型数据库,把存到关系型数据库的内容换到redis来存,那就是用redis来实现的cache。这样就出现了两种存储介质的数据的对比,这个数据的存储是有时间性的。当第一次浏览带有数据库查询的页面的时候,页面的数据先从数据库那里获取,获取完之后存一份到redis,比如存成string,articles_count: 100,意思是把文章的总数存到redis中。当存到redis时,我们可以设置过期时间,也可以让它永远不过期。第二次以及以后的访问,就会直接到redis去查找key为articles_count的是不是有值(数据过期就等于没有值),有的话,直接取,没有话,还是会取数据库,然后再放到redis。当你的真实的数据库记录更新的时候,比如这个时候增加了一篇文章,除了把这一篇文章存进数据库外,还要把redis中的对应的值改过来,这样就能保证取到最新的值的。
5. 页面哪些地方需要cache
现在以本站作为实例,来考虑下页面上哪些地方要使用cache。使用cache有个原则,就是这个页面部分的内容可能是耗时的,也有可能是很少改变的。比如底部,这个部分是基本不变的。

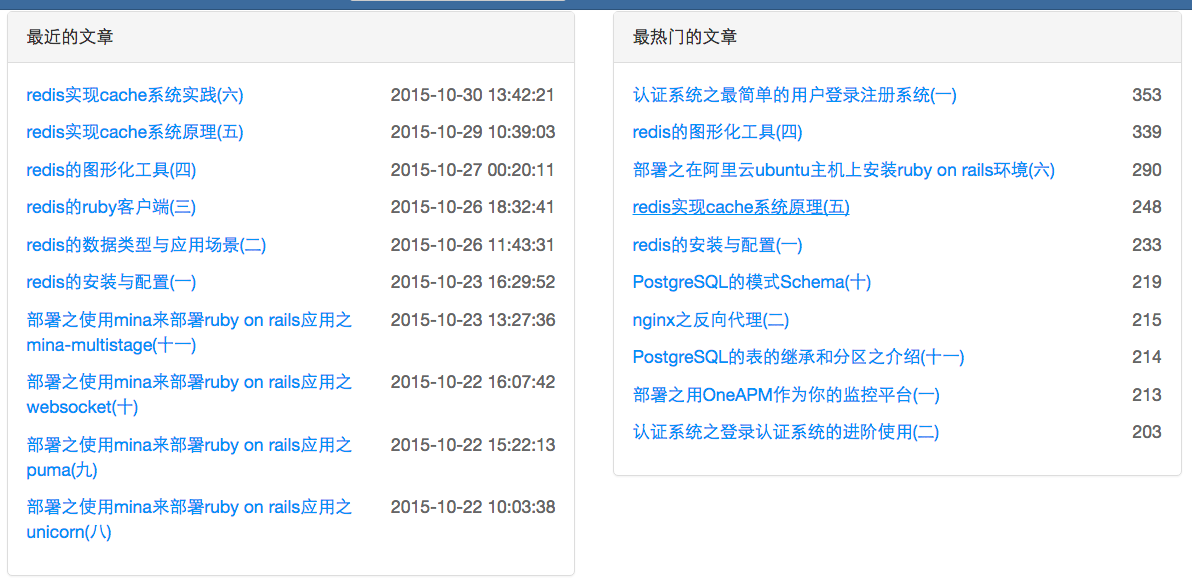
还有首页的中间部分"最近的文章"、"最热门的文章"、"所有的分类"部分,这部分的数据是取数据库的,我让它隔一段时间变一次或者有更改才变。
还有文章的内容页,这部分是用markdown写的,最终要转成有格式的html,如果先转好放到redis就能提高性能了。
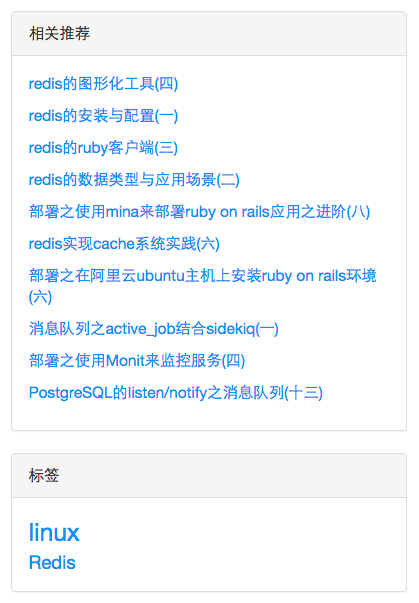
还有文章详情页的"相关推荐"和"标签“部分也是需要放到cache中的。
6. html片断cache
我们从数据库获取的数据最终还是要和html标签结合在一起,组装之后再给浏览器客户端,而这种就叫html片断,可以存放以string的方式存放在redis中。
完结。